
SF Opioid Crisis
San Francisco (SF) has a long history of pushing the envelope on progressive public health solutions, including medical cannabis and needle exchange, before either was legal or broadly embraced. It is so out of proportion, that California passed a bill allowing SF to open Safe Injection Sites (SIS).
Safe injection sites (SIS):
Safe injection sites are medically supervised facilities designed to provide a hy- gienic and stress-free environment in which individuals are able to consume illicit recreational drugs intravenously and reduce nuisance from public drug use. They are part of a harm reduction approach towards drug problems. North America’s first SIS Insite opened in the Downtown Eastside (DTES) neighborhood of Vancouver in 2003.
Potential Questions:
-
Comparing types of crime across different neighborhoods. What are the top 5 neighborhoods, where you can get assaulted? Do certain “pairs” of crime frequently co-occur together in a certain neighborhood?
-
Identifying potential neighborhoods for installing SIS for San Francisco government
Target Variable:
- Correlation between types of crime and neighborhoods from 2003 to 2018
- Do certain types of crime co-occur together frequently, or co-occur together in particular neighborhoods (i.e. association rule mining)
- Correlation between types of drugs used and neighborhoods from 2003 to 2018
- Identify potential neighborhoods/areas for San Francisco’s government to build safe injection sites
- Predict the type/category of crime-based on spatial and temporal features provided
Data:
Our data is collected from the San Francisco police department’s database. It is his- torical data regarding crimes from 2003 to May 2018. The dataset has 13 columns.
Analysis Approach:
- Perform data profiling using frequent statistics, and detect any outliers. For example, EDA/visualizations, null analysis. Semantic profiling to identify homogeneous columns - to eliminate extraneous features
- Create cluster-maps between crime type/category and neighborhoods - perform data normalization/standardization as necessary. Cluster-maps i.e. unsupervised learning, will help us to find the correlation between different neighbor- hoods and type of crime.
- Since this is a classification problem, we are using algorithms like XGBoost, CatBoost, Naive Bayes and Random Forest classifier with the response/target variable as the category/type of crime, and predictors as spatial-temporal columns. Hyperparamater tuning using k-folds cross-validation
- Preprocess data to filter out crimes that involved Drugs/Narcotics. Perform Step 1 on this subset again. Perform aggregations as necessary to get granu- lar information i.e. Narcotics based crimes categorized by types of drugs i.e. opioids, marijuana, etc.
- Create cluster-maps between different types of drugs and neighborhoods. Normalize or standardize data as required
- Encode the data to a transactional form - execute Apriori and FP-growth to find interesting patterns (i.e association rules). Comparative study : FP- Growth vs Apriori
Results:
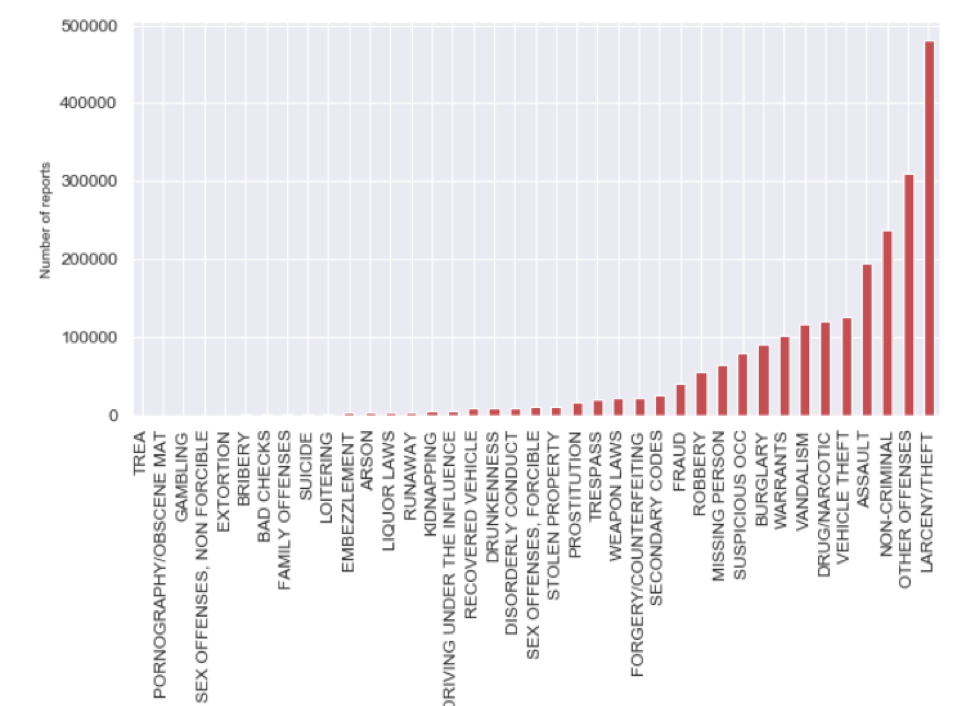
Distribution of categories of crimes from 2003 to 2018:
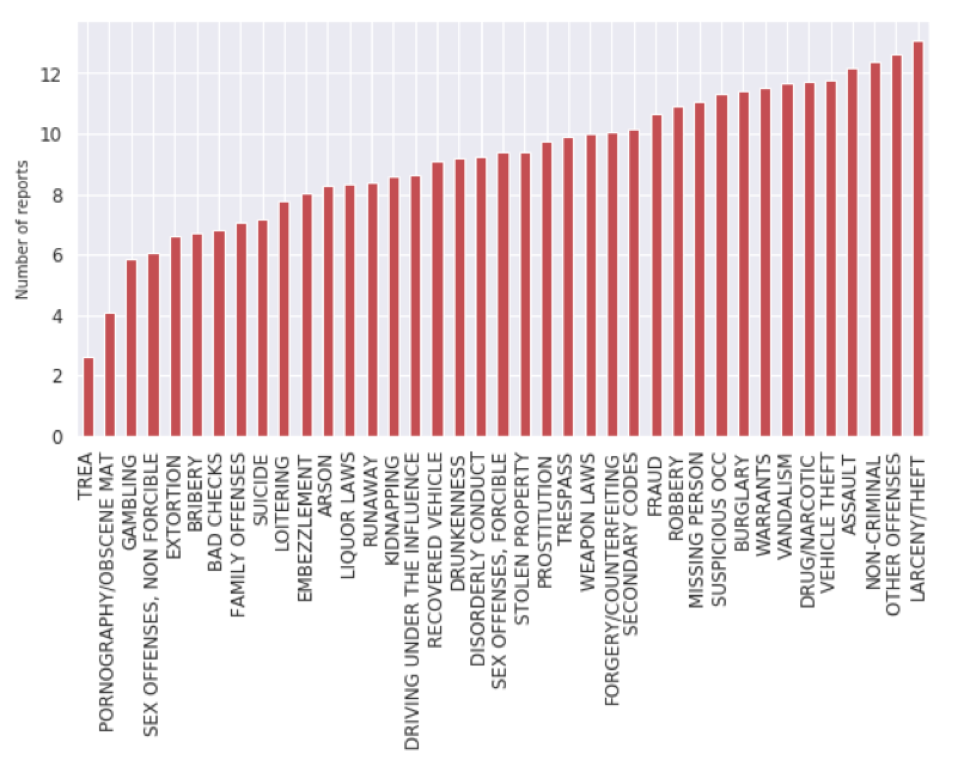
After Normalization:
Cluster-maps b/w categories of crimes vs neighborhoods:
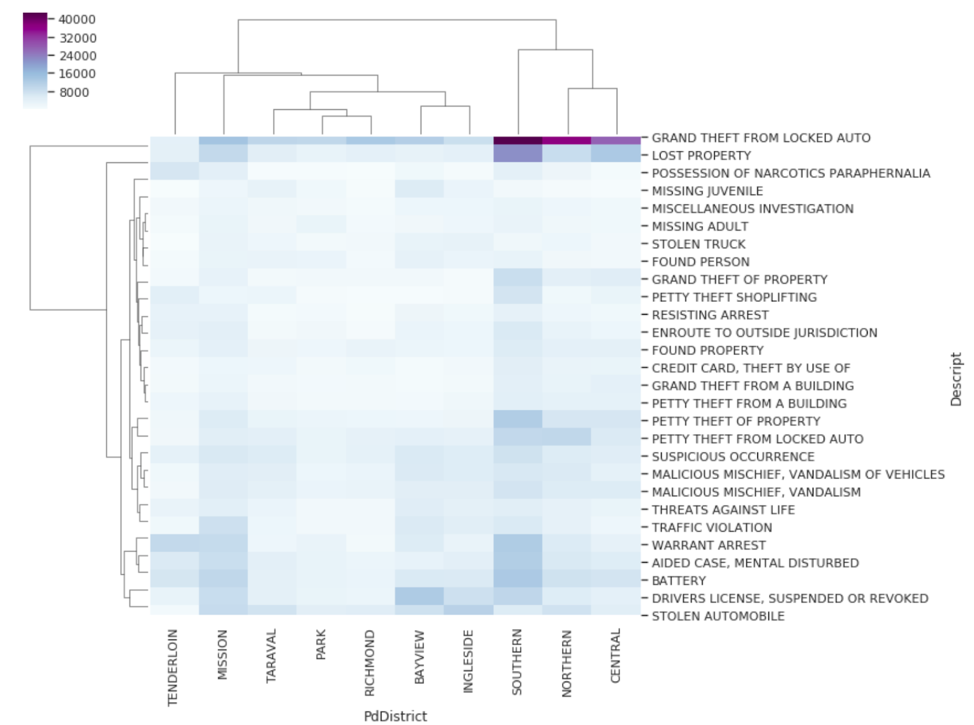
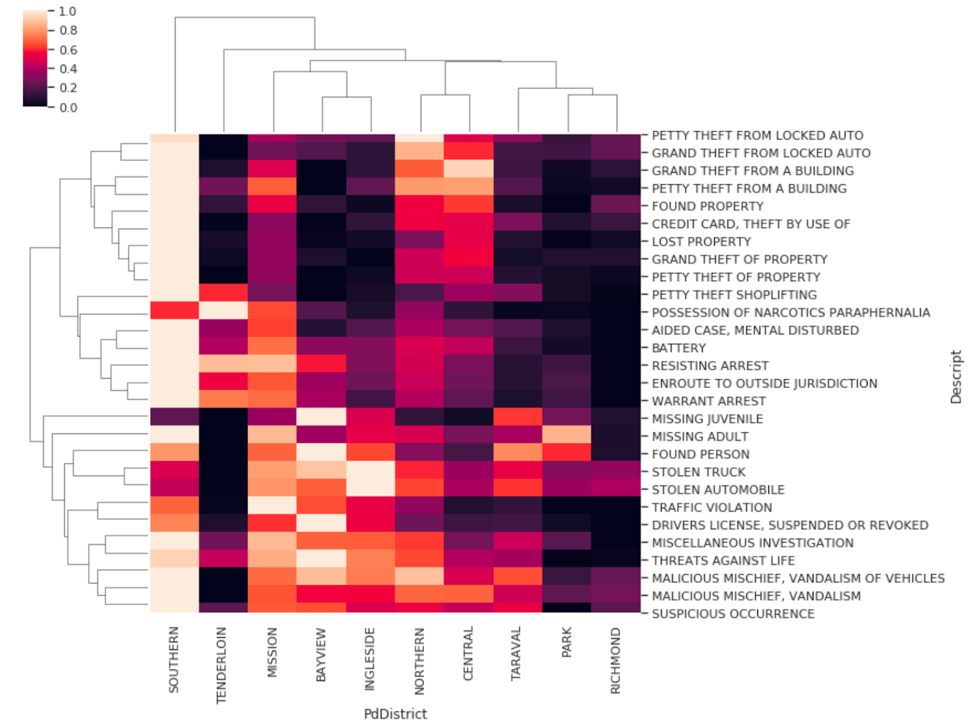
Cluster-maps b/w different opioids & neighborhoods:
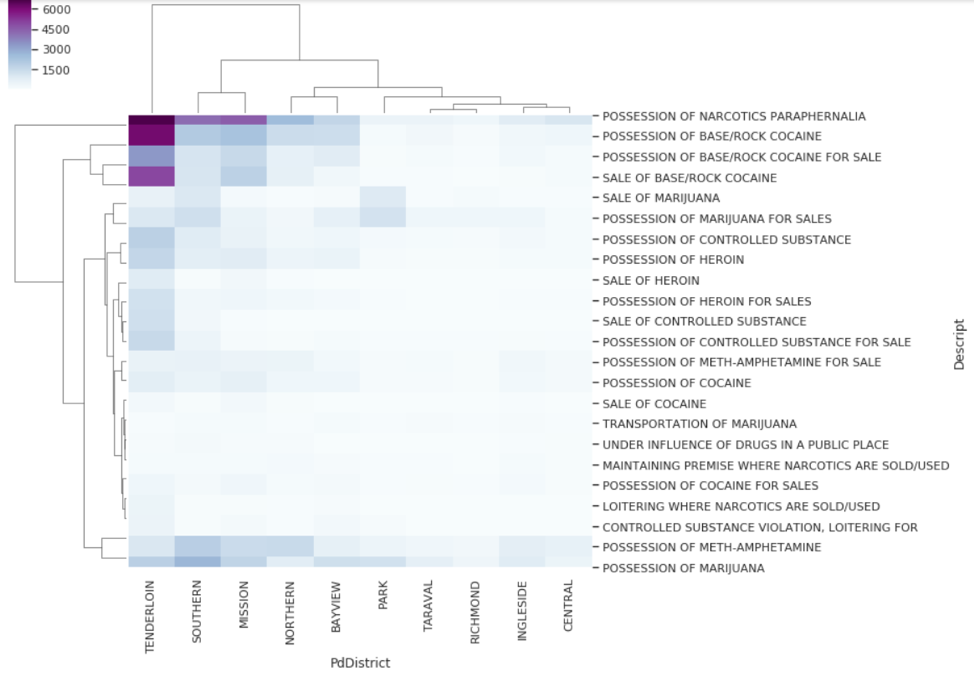
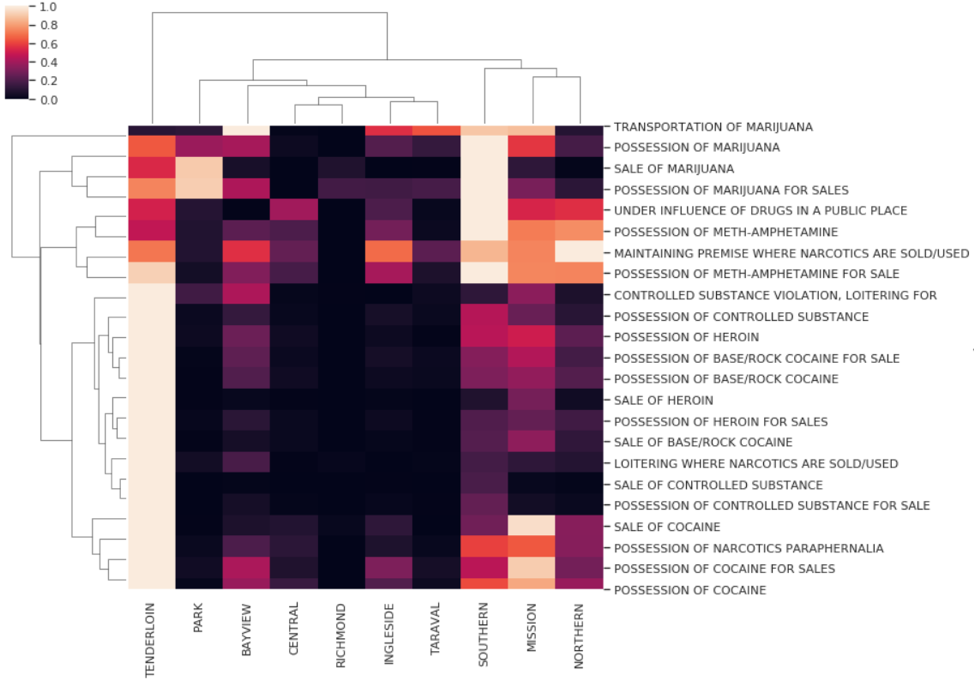
Specific Opioid Distributions across time:
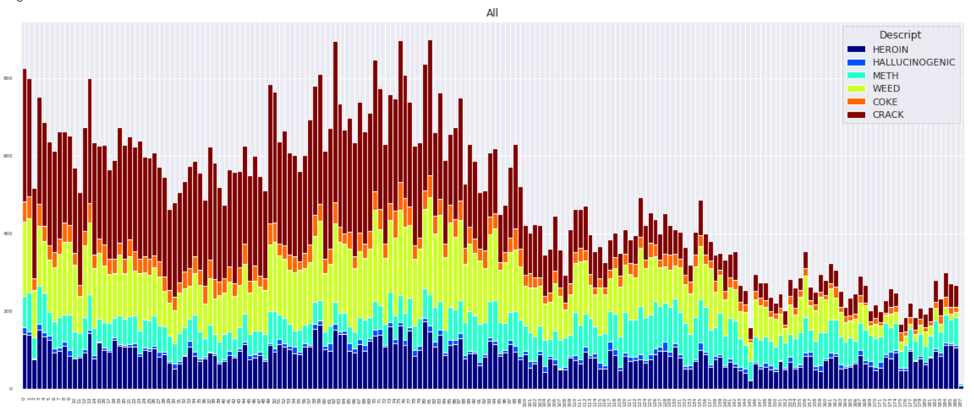
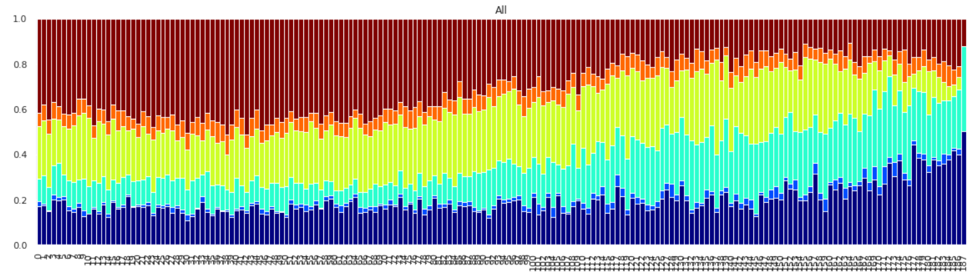
Opioid Distributions across years:
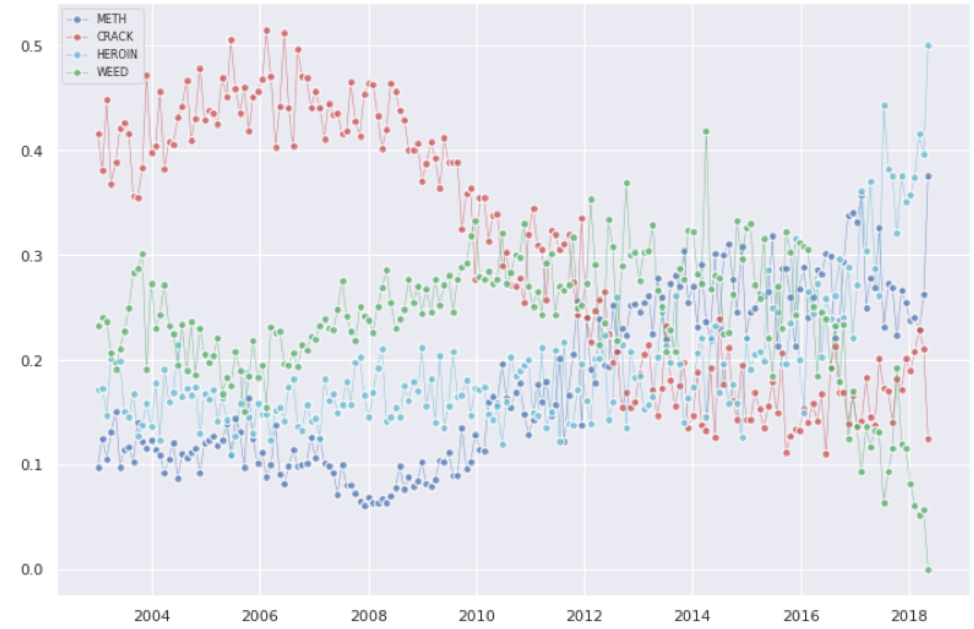
Check the code for the application here: Crisis



Comments